Wonderlandhttps://github.com/waynexia.png2024-04-23T13:06:33.955Zhttps://waynexia.github.io/WayneHexoHow error occurs in GreptimeDBhttps://waynexia.github.io/2024/01/rust-stack-error/2024-01-22T00:53:48.000Z2024-04-23T13:06:33.955Z
TL;DR:
This post discusses the practice of Rust error handling topic in GreptimeDB. Including how to build a cheaper yet more accurate error stack to replace system backtrace, how to organize errors in large project and how to print errors in different schemes to log and end users. And shares possibly future work in the end.
An example of error in GreptimeDB looks like:
1 2 3
0: Foo error, at src/common/catalog/src/error.rs:80:10 1: Bar error, at src/common/function/src/error.rs:90:10 2: Root cause, invalid table name, at src/common/catalog/src/error.rs:100:10
Introduce
What Error is in Rust
In Rust, functions that might fail usually return a special enum Result<T, E>, where E usually implements the trait std::error::Error. This is the fundamental of error handling.
This blog shares our experience on how to organize variant types of Error in a relatively complex system like GreptimeDB, which is composed of multiple components with their own Error definition. From how an error is defined to how to present an error to log or end-user.
Ecosystem at present
There are some Error structs in std that implement std::error::Error, like std::io::Error or std::fmt::Error. But we would usually define one for our project, as either we want to express our own error info or we may face multiple errors at the same time.
Given the std::error::Error trait is not complicated, it’s easy to implement manually for the customized error type. However you usually won’t want to do so. When error variants increase, it might be hard to work with flooding template code. Nowadays, there are some widely used utility crates to help play around with customized error types, like thiserror and anyhow, from the same author. Said that, use thiserror for library project and anyhow for binary project. This rule suits a major number of cases.
But for projects like GreptimeDB, where we divide the entire workspace into several individual sub-crates, we need to define an error type for each crate while keeping a streamlined combination. Neither thiserror nor anyhow can achieve this easily.
Here we choose another crate snafu to instrument our error system. It’s like a combination of thiserror and anyhow. thiserror provides a convenient macro to define customized error type, with display, source and some context fields. And anyhow gives a Context trait that can easily transform from one underlying error into another with a new context.
thiserror mainly implements the std::convert::From trait for your error type, so that you can easily use ? to propagate the error you receive. Consequently, this also means you cannot define two error variants that come from the same source. Considering you are performing some I/O operations, you won’t know whether an error is generated in write or read. This is also an important reason we don’t use thiserror – the context is blurred in type.
Stacking Error
What we want from error
In the real world, only knowing what an error is is far not enough. Imagine we are building a little protocol component in GreptimeDB (or any other project, just for example), It reads messages from the Internet, decodes, performs some operations and then sends it. We may encounter errors from several aspects:
When an error occurs, it might look like DecodeMessage(serde_json: invalid character at 1). But this component might have 10 places that decode the message! How can we figure out in which step we see the invalid content?
So despite the error itself telling what has happened, if we want to have a clue on where this error occurs and if we should pay attention to it, we need the error to carry more information. For comparison, here is an example of an error log you might see from GreptimeDB.
1 2 3 4 5
Failed to handle protocol 0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22 1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14 2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14 3: serde_json(invalid character at position 1)
A good error is not only about how it’s constructed, but more importantly is what will human see from it. We call it Stack Error. It should be intuitive and you must have seen a similar format elsewhere like backtrace.
From this log, it’s easy to know the entire thing with full context, from the user-facing behavior to the root cause. Plus the exact line and col number of where each error is propagated. And even gain a tiny report of this error: “in the query “blabla”, the fifth package’s header is corrupted”. It’s likely to be an invalid user input and we may not need to handle it from the server side.
This example shows the critical information that an error should contain (and contains in GreptimeDB):
The root cause. Tells what’s happening.
The full context stack. For debugging or figuring out where this occurs.
What happens from the user’s perspective. Decide whether we need to expose this to user.
The first root cause is often clear in many cases, like the DecodeMessage example before. Only if the library or function we used implements their error type correctly. But sometimes it isn’t quite helpful if we only have the root cause. Here is another example from DataBricks.
In the following sections, we will focus on the next two points and explain how it’s achieved. So hopefully you can achieve the same experience as in GreptimeDB.
System Backtrace
So, now you have the root cause (DecodeMessage(serde_json: invalid character at 1)) but it’s not clear at which step this error occurs. Is decoding the header or body?
A natural thought is to capture the backtrace. In a causal where .unwrap() is the first choice, the backtrace will show up when error occurs (of course this is a bad practice). It will give you a complete call stack along with the line number. Then inspect the source code stack by stack, after skipping lots of unrelated system stacks, runtime stacks and std stacks, you finally get to the code you write.
Nowadays many libraries also provide the ability to capture backtrace on an Error is constructed. Regardless of whether the system backtrace can provide what we truly want, it’s very costly on either CPU (#1261) and memory (#1273). Capturing a backtrace will slow down your program as it needs to walk through the call stack and translate the pointer. Then to be able to translate the stack pointer we will need to include a large debuginfo in our binary. In GreptimeDB this means increasing the binary size by > 700MB (4x size compared to 170MB without debuginfo). And there will be many noises in the captured system backtrace because the system can’t distinguish whether the code comes from the standard library, a third-party async runtime or our codebase.
There is another difference between the system backtrace and the proposed stack error. System backtrace tells us how to get to the position where the error occurs. While the stack error shows how the error is propagated. Sometimes there are different things. This difference comes from how the two things are implemented.
Virtual User Stack
Now let’s introduce the virtual user stack. The word “virtual” means the contrast of the system stack. Means it’s defined and constructed fully on user code. Look closer into the previous example:
1
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
A stack layer is composed of 3 parts. The first number represents its position in the entire stack. Then follows the description of this layer, which is the std::fmt::Display implementation of that error. The last is corresponding code location. Rust provides file!, line! and column! macros to help get that information.
In practice, we utilize snafu::Location to gather the code location. So each location points to where the error is constructed. Through this chain we know how this error is generated and propagated to the uppermost.
So here is what it looks like all together:
1 2 3 4 5 6 7 8
#[derive(Snafu)] pubenumError { #[snafu(display("General catalog error: "))]// <-- the `Display` impl deriv Catalog { location: Location, // <-- the `location` source: catalog::error::Error, // <-- inner cause } }
Then we implemented a proc-macro stack_trace_debug to scrape necessary information from Error‘s definition and generate the implementation of the related trait StackError, which provides useful methods to access and print the error:
By the way, we have added Location and display to all errors in GreptimeDB. This is the hard work behind the methodology.
Macro Details
Error is a singly linked list, like an onion from outer to inner. So we can capture an error at the outermost and walk through it.
One tricky thing we did here is about how to distinguish internal and external errors. Internal errors all implement the same trait ErrorExt which can be used as a marker. But depending on this requires a downcast every time. We avoid this extra downcast call by simply giving a different name to them and detect in our macro. As shown below, we name all external errors error and all internal errors source. Then return None on implementing StackError::next method if we find an error, or Some(source) if we read source.
The method StackError::debug_fmt is used to render the error stack. It would be called recursively in the generated code. Each layer of error will write its own debug message to the mutable buf. The content will contain error description captured from #[snafu(display)] attribute, the variant arm type like TableEngineNotFound and the location from the enumeration.
Given we already defined our error types in that way, adopting stack error doesn’t require too much work, only adding the attribute macro #[stack_trace_debug] to every error type would be enough.
Present Error to End User
So far we have done the most things. Here is the last piece about how to present the error to your user.
Unlike the developer of your system, a user may not care about the line number and even the stack. But what information is helpful to end users?
This topic is very subjective. Our experience is that the leaf (or the innermost) error’s message might be useful as it is closer to what really goes wrong. The message can be further divided into two parts: internal and external, where the internal error is those defined in our codebase and the external is from dependencies, like serde_json from the previous example. And the root (or the outermost) error’s category is more accurate as it comes from where the error is thrown to the user. This can be achieved easily with previous StackError::next and StackError::last. Or you can customize the format you want with those methods.
Combine them, here is the schema of our error that the user would see eventually:
1
KIND - REASON ([EXTERNAL CAUSE])
For example:
1
Unexpected Message - Failed to decode `01010001001010001` to ProtocolHeader (serde_json(invalid character at position 1))
Cost?
The virtual stack is sweety so far. And is cheaper and more accurate than the system backtrace. How much does it cost?
As for runtime overhead, it only requires some string format for the per-level reason and location.
And it’s even better on binary size. In GreptimeDB’s binary, the debug symbols occupied ~ 700MB, as a comparison the strip-ed binary size is around 170MB, with .rodata section size 016a2225 (~ 22.6M), the .text section occupies 06ad7511 (~ 106.8M).
Removing all Location reduces the .rodata size to 0169b225 and the overall binary size to 170MB. while removing all #[snafu(display)] reduces the .rodata size to 01690225 (~ 22.5M) and the overall binary size to 170MB. Hence this stack error mechanism’s overhead to binary size is very low (~ 100K).
Conclusion and Future Work
In this post, we present how to implement a proc-macro stack_trace_debug and use it to assemble a low-overhead and powerful stack error message. It also provides a convenient way to walk through the error chain, to help render the error in different schema for different purposes.
This macro is only adopted in GreptimeDB now, we are attempting to make it more generic for different projects. A wide adoption of this pattern can also make it even more powerful by bringing more third-party stacks and detailed reasons.
An unstable API provide in std Error allows getting a field in a struct. It’s an option we can consider for refactoring our stack-trace utils.
]]><blockquote>
<p>TL;DR:</p>
<p>This post discusses the practice of Rust error handling topic in GreptimeDB. Including how to build a cheaper 雪国https://waynexia.github.io/2024/01/yukiguni/2024-01-10T21:25:18.000Z2024-04-23T13:06:33.963Z2024 年元旦出游的一些照片,题图是结冰的三笠市桂沢湖。
夕张是上个世纪的一个资源城市,六十年前人口还有十一万,现在已经只剩六千余了,是日本人口第二少的城市。因为周围煤炭资源逐渐减少,城市也慢慢萎缩下来。老夕张站已经废止了,这里的新夕张站看上去也没有很好。车站楼外壳也全部生了铁锈,连 JR 的标志都没有。洗手间还在运营,但工作人员三点钟就下班了(羡慕!)。有点好奇在这里上班的人一天的行程。
]]><blockquote>
<p><em>What I am composed of</em></p>
</blockquote>
<h1 id="冬"><a href="#冬" class="headerlink" title="冬"></a>冬</h1><p> <em>数Querying Prometheushttps://waynexia.github.io/2023/11/querying-prometheus/2023-11-23T16:13:33.000Z2024-04-23T13:06:33.955ZExplain PromQL in simple SQL that you are familiar with.
This blog is work-in-progress. But you can still read and discuss it with me.
Planned content:
select data
operations
format in storage
joins, group and set operation
get distributed
extension on types and operations
counter, histogram and summary
Select data
Prometheus collects data in an unreliable way. The data process pipeline has considered and brings lots of “special logic” to make those unreliable data look reasonable and intuitive. But as the price, that logic might not be straightforward as a traditional SQL-based database. This section includes lookback, null-handling, offset, interval.
Notice that those mechanisms always take effort together. To keep the explanation dry, other cases are ignored when explaining one (E.g., “offset” section assumes there is no “lookback”).
offset
This is the simplest one. Offset is used to “bias” the data’s timestamp – every data point in Prometheus has a related timestamp, as well as the query itself. In SQL, the table (Prometheus names it “metric”) looks just like this:
The offset provides a way to push backward (toward an earlier time) the time range of querying:
1
SELECT ... FROM metric WHERE ts >= (START-OFFSET) and ts < (END-OFFSET);
For example, if we query data between 2023-11-14T18:00:00Z and 2023-11-14T22:00:00Z, and with “1h” offset, the equal SQL would be something like below:
1
SELECT ... FROM metric WHERE ts >='2023-11-14T17:00:00Z'AND ts <'2023-11-14T21:00:00Z'
Another point is the offset can be negative. In this case, you are just “minus a negative”
interval
You might be wondering why the results from Prometheus step are aligned to the given resolution but not the data collection interval. Here is an example result part I get with 7s resolution:
That’s because Prometheus doesn’t generate timestamp directly from the data’s timestamp, but in a reversed way, where the timestamp in the result is determined first, then finds values suited for that timestamp and feeds them into calculate operators. The interval is one of the key parameters for determining the timestamps in result. It works very simply – if we use a for loop to simulate this behavior, it would be
1
for (ts = start; ts < end; ts += interval) {}
lookback
Also, unlike SQL where filter filters the “exact” what you require, PromQL will take its liberty to find data out the range of your query and present them to you. This behavior is called “lookback”, looking at a larger range and fetching data for calculation. For example, if the current timestamp we are calculating is 1700000000 (2023-11-14T22:13:20Z), and lookback delta is ‘5m’ (300s). The filter is not WHERE ts = 1700000000, but this:
1
SELECT ... FROM metric WHERE ts >=1699999700AND ts <=1700000000;
That is, Prometheus will take up to 5 minutes of data into consideration when calculating one data point.
null handling
TODO
don’t repeat
Though Prometheus will try its best to find data, but it won’t grab a repeated dataset for calculation, where all the points are the same, i.e., it won’t repeat on one point to fill absent timestamps.
]]><p>Explain PromQL in simple SQL that you are familiar with.</p>
<blockquote>
<p>This blog is work-in-progress. But you can still read and di原子之心https://waynexia.github.io/2023/08/atomic-heart/2023-08-30T22:54:53.000Z2024-04-23T13:06:33.951Z从概念图和 PV 开始就溢出屏幕的复古科幻的味道让人非常心动,而且首发 XGP 完全没有门槛。
虽然美术音乐设定等等都和上乘,但是作为游戏本身的 game play 部分还是让人有点头疼(字面)。虽然是在一个很不错的场景里,但是没过多久就丧失了探索的欲望。在路上满是怪物,如果不是也马上就是了。敌人超远的索敌范围,联动和增殖机制,使得在户外的时候永远别想停下来。而与此相对的是较低的收益和较差的攻击体验,苦苦战斗不如直接逃跑。还有随处可见的有形围墙,以及不可见的 bug 形成的空气陷阱,不沿着主路走马上就会教你后悔。
fnpoll_future() -> FutureOutput { match status_of_the_task { Ready(output) => { // the task is finished, and we have it output. // some logic return our_output; }, Pending => { // it is not ready, we don't have the output. // thus we cannot make progress and need to wait return Pending; } } }
fnruntime(&self) { loop { let future_tasks: Vec<Task> = self.get_tasks(); for task in tasks { match task.poll_future(){ Ready(output) => { // this task is finished. wake it with the result task.wake(output); }, Pending => { // this task needs some time to run. poll it later self.poll_later(task); } } } } }
// If the task is running, we mark it as cancelled. The thread // running the task will notice the cancelled bit when it // stops polling and it will kill the task. // // The set_notified() call is not strictly necessary but it will // in some cases let a wake_by_ref call return without having // to perform a compare_exchange. snapshot.set_notified(); snapshot.set_cancelled();
To determine whether your own methods are cancellation safe, look for the location of uses of .await . This is because when an asynchronous method is cancelled, that always happens at an .await . If your function behaves correctly even if it is restarted while waiting at an .await , then it is cancellation safe.
val startTime = System.currentTimeMillis() val job = launch(Dispatchers.Default) { var nextPrintTime = startTime var i = 0 while (isActive) { // cancellable computation loop // print a message twice a second if (System.currentTimeMillis() >= nextPrintTime) { println("job: I'm sleeping ${i++} ...") nextPrintTime += 500L } } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
- for db_req in batch_req.databases { - for obj_expr in db_req.exprs { - let object_resp = self.query_handler.do_query(obj_expr).await?; - db_resp.results.push(object_resp); + let (tx, rx) = oneshot::channel(); + let query_handler = self.query_handler.clone(); + let _ = self.runtime.spawn(async move { + // execute request in another runtime to prevent the execution from being cancelled unexpected by tonic runtime. + let mut result = vec![]; + for db_req in batch_req.databases { + for obj_expr in db_req.exprs { + let object_resp = query_handler.do_query(obj_expr).await; + + result.push(object_resp); + } }
现在一切正常了。
]]><h1 id="The-Problem"><a href="#The-Problem" class="headerlink" title="The Problem"></a>The Problem</h1><p>这篇博客会讲一个在<a target="_blank" rel="nThe Hidden Control Flowhttps://waynexia.github.io/2022/12/async-cancellation/2022-12-04T16:06:19.000Z2024-04-23T13:06:33.951ZThe Problem
This post is talking about a “weird” problem we encountered in GreptimeDB. And, a little spoiler, it’s about the “async cancellation”.
Let’s first describe the (simplified) scenario. We observed metadata corruption in a long-run test. A series number is duplicated, but it should be increased monotonously. The update logic is very straightforward – load value from an in-memory atomic counter, persist the new series number to file, and then update the in-memory counter. The entire procedure is serialized (file is a mutable reference):
For some reason, we are not using fetch_add here, though it does work, and if we’ve done so, then the story won’t happen 🤪 For example, we don’t want to update the in-memory counter when this procedure fails halfway, like operation persist_number() cannot write to the file. Here the sweet sugar ? stands for such a situation. We know clearly that this function call may fail, and if it fails the caller returns early to propagate the error. So we will handle it carefully with that in mind.
But things become tricky with .await, the hidden control flow comes due to async cancellation.
Async Cancellation
async task and runtime
If you have figured out the shape of the “criminal”, you may want to skip this section. Instead, I’ll start with some pseudocode to show what happens in the “await point”, and how it interacts with the runtime. First is poll_future, it comes from the Future‘s poll function, as every async fn‘s we write will be desugared to an anonymous Future implementation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14
fnpoll_future() -> FutureOutput { match status_of_the_task { Ready(output) => { // the task is finished, and we have it output. // some logic return our_output; }, Pending => { // it is not ready, we don't have the output. // thus we cannot make progress and need to wait return Pending; } } }
async block usually contains other async functions, like update_metadata and persist_number. Say persist_number is a sub-async-task of update_metadata. Each .await point will be expanded to something like poll_future – awaiting the subtask’s output and make progress when the subtask is ready. Here we need to wait persist_number‘s task returns Ready before we update the counter, otherwise we cannot do it.
And the second one is a (toy) runtime, which is in response to poll futures delivered to it. In GreptimeDB we use tokio as our runtime. An async runtime may have tons of features and logic, but the most basic one is to poll: as the name tells, keep running unfinished tasks until they finish (but consider the things I’m going to write later, the “until” might not be a proper word).
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
fnruntime(&self) { loop { let future_tasks: Vec<Task> = self.get_tasks(); for task in tasks { match task.poll_future(){ Ready(output) => { // this task is finished. wake it with the result task.wake(output); }, Pending => { // this task needs some time to run. poll it later self.poll_later(task); } } } } }
That is it, a very minimalist model of future and runtime. Combining these two functions, you will find that in some aspects, it is just a loop (again, I’ve omitted lots of details to keep tight on the topic; the real world is way more complex). I want to stress the thing that each .await imply one or more function calls (call to poll() or poll_future()). This is the “hidden control flow” in the title and the place cancellation takes effort.
Know it is not hard, but thinking about it is not easy (at least for me). I’ve stared at these lines for minutes after I narrow the scope down to as simple as the first code snippet. I know the problem is definitely in the .await. But don’t know whether too many successful async calls have numbed me or my mental model hasn’t linked these two points. The bulky garbage, me, spent a whole sleepless night doubting life and the world.
cancellation
So far is the standard part. We will then talk about cancellation, which is runtime-dependent. Though many runtimes in rust have similar behavior, this is not a required feature, i.e., a runtime can not support cancellation at all like this toy. And I’ll take tokio as an example because the story happens there. Other runtimes may be similar.
In tokio, one can use JoinHandle::abort() to cancel a task. Tasks have a “cancel marker bit” tracks whether it’s cancelled. And if the runtime finds a task is cancelled, it will kill that task (code from here):
1 2 3 4 5 6 7 8 9
// If the task is running, we mark it as cancelled. The thread // running the task will notice the cancelled bit when it // stops polling and it will kill the task. // // The set_notified() call is not strictly necessary but it will // in some cases let a wake_by_ref call return without having // to perform a compare_exchange. snapshot.set_notified(); snapshot.set_cancelled();
The theory behind async cancellation is also elementary. It’s just the runtime gives up to keep polling your task when it’s not yet finished, just like ? or even tougher because we cannot catch this cancellation like Err. But does it means that we need to take care of every single .await? It would be very annoying. Take this metadata updating as an example. If we have to consider this, we need to check if the file is consistent with the memory state and revert the persisted change if found inconsistency. Well… 🫠 In some aspects, yes. The runtime can literally do anything to your future. But the good thing is that most of them are disciplined.
Runtime Behavior
This section will discuss what I would expect from a runtime and what we can get for now.
marker trait
I want the runtime not to cancel my task unconditionally and turn to the type system for help. This is wondering if there is a marker trait like CancelSafe. For the word cancellation safety, tokio has said about it in its documentation:
To determine whether your own methods are cancellation safe, look for the location of uses of .await . This is because when an asynchronous method is cancelled, that always happens at an .await . If your function behaves correctly even if it is restarted while waiting at an .await , then it is cancellation safe.
That is, whether a task is safe to be cancelled. This is definitely an “attribute” of an async task. You can find that tokio has a long list of what is safe and what isn’t in the library from the above link. And, in some ways, I think it’s just like the UnwindSafe marker. Both are “this sort of control flow is not always anticipated“ and “has the possibility of causing subtle bugs“.
With such a CancelSafe trait, we can tell the runtime if our spawned future is ok to be cancelled, and we promise the “cancelling” control flow is carefully handled. And if without this, means we don’t want the task to be cancelled. Simple and clear. This is also an approach for the runtimes to require their users (like you and me) to check if their tasks are able to be cancelled. Take timeout() as an example:
1 2 3 4 5 6 7
/// The marker trait traitCancelSafe {}
/// Only cancellable task can be timeout-ed pubfntimeout<F>(duration: Duration, future: F) -> Timeout<F> where F: Future + CancelSafe {}
volunteer cancel
Another approach is to cancel voluntarily. Like the cooperative cancellation in Kotlin, it has an isActive method for a task to check if it is cancelled. And this is only a tester method, to cancel or not is fully dependent on the task itself. I paste an example from Kotlin’s document below, the “cooperative cancellation” happens in line 5. This way brings the “hidden control flow” on the table and makes it more natural to consider and handle the cancellation just like Option or Result.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
val startTime = System.currentTimeMillis() val job = launch(Dispatchers.Default) { var nextPrintTime = startTime var i = 0 while (isActive) { // cancellable computation loop // print a message twice a second if (System.currentTimeMillis() >= nextPrintTime) { println("job: I'm sleeping ${i++} ...") nextPrintTime += 500L } } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
And this is not hard to achieve in my opinion. Tokio already has the Cancelled bit and CancellationToken. But they look a bit different than what I describe. And after all of these, we need runtime to give the cancellation right back to our task. Or the situation might not have big difference.
explicit detach
Can we force the runtime not to cancel our tasks at present? In tokio we can “detach” a task to the background by dropping the JoinHandle. A detached task means there is no foreground handle to the spawned task, and in some aspect, others cannot wrap a timeout or select over it, making it un-cancellable. And the problem in the very beginning is solved in this way.
A JoinHandledetaches the associated task when it is dropped, which means that there is no longer any handle to the task, and no way to join on it.
Though there is the functionality, I would wonder if it’s better to have an explicit detach method like glommio's, or even a detach method in the runtime like spawn, which doesn’t return the JoinHandle. But these are trifles. A runtime usually won’t cancel a task for no reason, and in most cases, it’s required by the users. But sometimes you haven’t noticed that, like those “unselect branches” in select, or the logic in tonic‘s request handler. And if we are sure that a task is ready for cancellation, explicit detach may prevent it from tragedy sometime.
Back To The Problem
So far everything is clear. Let’s start to wipe out this bug! First is, why our future is cancelled? Through the function call graph we can easily find the entire process procedure is executed in-place in tonic‘s request licensing runtime, and it’s common for an internet request to have a timeout behavior. And the solution is also simple, just detaching the server processing logic into another runtime to prevent it from cancelled with the request. Only a few lines:
- for db_req in batch_req.databases { - for obj_expr in db_req.exprs { - let object_resp = self.query_handler.do_query(obj_expr).await?; - db_resp.results.push(object_resp); + let (tx, rx) = oneshot::channel(); + let query_handler = self.query_handler.clone(); + let _ = self.runtime.spawn(async move { + // execute request in another runtime to prevent the execution from being cancelled unexpected by tonic runtime. + let mut result = vec![]; + for db_req in batch_req.databases { + for obj_expr in db_req.exprs { + let object_resp = query_handler.do_query(obj_expr).await; + + result.push(object_resp); + } }
Now all fine.
]]><h1 id="The-Problem"><a href="#The-Problem" class="headerlink" title="The Problem"></a>The Problem</h1><p>This post is talking about a “weirPaper Reading: CURP protocolhttps://waynexia.github.io/2022/09/curp-notes/2022-09-18T17:58:33.000Z2024-04-23T13:06:33.955Z论文名字是《Exploiting Commutativity For Practical Fast Replication》
To avoid duplicate executions of the requests that are already replicated to backups, CURP relies on exactly-once semantics provided by RIFL, which detects already executed client requests and avoids their re-execution
even if a value is replicated to some of backups, the value may get lost if the master crashes and a new master recovers from a backup that didn’t receive the new value. A simple solution for this problem is that backups don’t allow reading values that are not yet fully replicated to all backups.
]]><p>论文名字是《Exploiting Commutativity For Practical Fast Replication》</p>
<p>CURP全称Consistent Unordered Replication Protocol,主要是利用操作之间的相关性(CommuCeresDB 的单线程模型实践 (Rust China Conf 2022)https://waynexia.github.io/2022/06/tpc-practice/2022-06-16T12:46:10.000Z2024-04-23T13:06:33.963Z
这篇是从 Rust China Conf 2022 的 talk 整理来的(校对听写转录稿好麻烦……
(还没校对完)
介绍一下单线程模式两个在生产中的例子,HelixDB 是一个Thread Per Core模型的KV存储,CeresDB 中也有部分逻辑在单线程模式下工作。
另外一个问题就是强制分区,因为我们希望各个线程之间尽量减少交流来减少额外开销,所以能够最好就是预先将工作负载和资源都进行划分,比如CeresDB是按照表来进行partition,可能别的系统还按照ID或 Key range之类的。对一些系统来说可能分区是比较简单的,但是对于另外一部分系统,它可能就比较难以找到一个合适的分区方式,那我们这种单线程的编程模型或者是Thread Per Core不太适合。
另外也有一些专门为Thread Per Core模型设计的运行时,比如说glommio和monoio,不过这两个除了Thread Per Core之外还绑定了io_uring作为IO接口,虽然非常合理,因为我们本身就是最好是能够和异步IO相结合使用,但是也让它没有那么灵活,因为作为一个还比较新的系统特性,可能很多存量的服务器系统版本还没有升级,可能就会需要用到我们刚刚提到的那些手段去做一个适配。
还有标准库中的一些工具类也能够派上用场,比如用TLS代替一些全局变量,它们也属于被分开的“状态”。在刚刚提到我们使用tokio来模拟Thread Per Core Runtime的时候,也有使用到TLS,就是把每个线程拥有一个正常的tokio Runtime,然后把它放在TLS里面来模拟一个Thread Per Core Runtime。
]]><p>这是系列第二作。但是从一些之前的资料来看一开始冰点之下是作为第一部的 DLC 的身份面世的,不过我在 xbox 商店看到的时候它已经和《深海迷航》分开成两个条目了,也许是做着做着就拿出来单独售卖了吧。不过可能是这个原因,冰点之下大部分的元素基本和之前一模一样,画面和操作都是杂技:被 CGO 玩转https://waynexia.github.io/2021/12/embed-rust-lib-into-go/2021-12-28T19:58:27.000Z2024-04-23T13:06:33.955Z背景
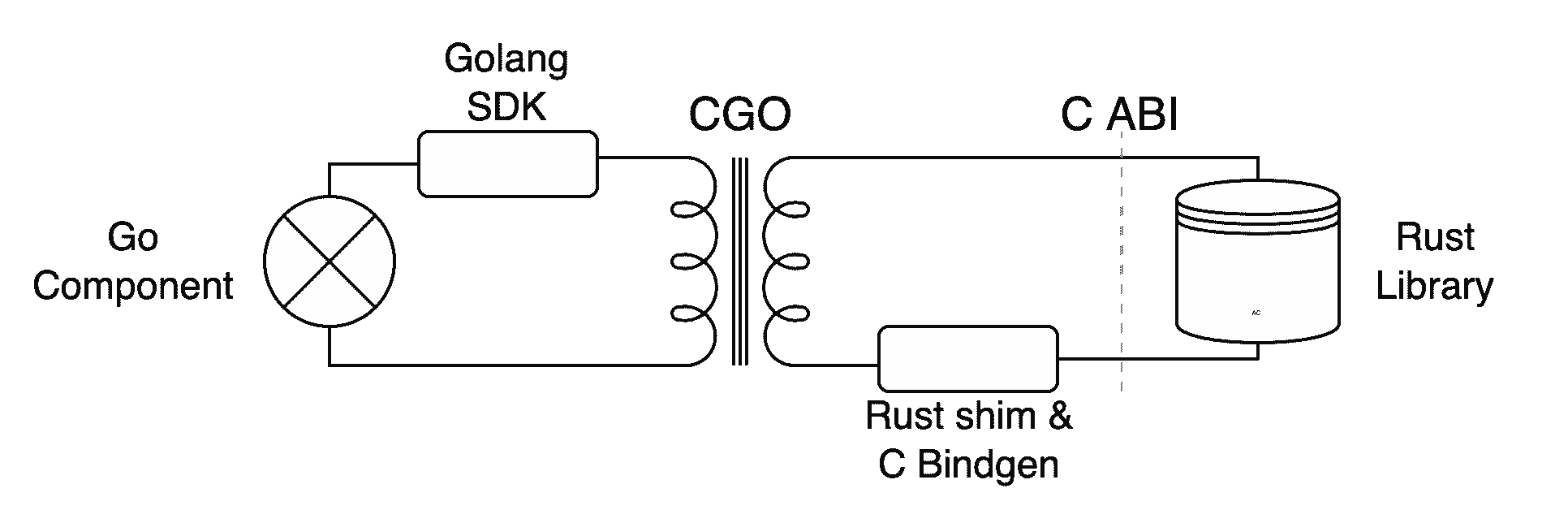
故事发生在蚂蚁一个内部项目上,这个项目有 Go 和 Rust 两个部分,其中 Rust 库作为一个存储组件被 Go 的业务部分依赖着。出于种种原因,两个部分需要作为同一个进程来运行,中间有一层 C FFI 接口作为理想与现实的桥梁。大概是这个样子的
Rust 部分首先将使用到的 Library 的接口和结构使用另一个小小的 cdylib shim 项目封装一下,并通过这个项目生成 Rust 库的编译产物、一个动态链接对象和一份 C 的接口头文件。再基于 C header 写一个 Go 的 SDK 给上层使用。单独左边的 Go 或者右边的 Rust 项目都不够刺激,连在一起就很得劲了。这里主要集中在中间那一团麻花部分上,也是 too young too simple 掉了很多头发的地方。
Go 与 Rust 在远离 FFI 边界的地方(一般来说)都能够很好地处理内存问题,这些非法的指针和地址基本上都是没能好好处理另一方丢过来的东西造成的。在当时为了减少工作量已经通过大量的拷贝减少了许多使用裸指针的地方,剩下的主要集中在两处,即接收对方传递过来的数据以及通知对方回收这一块数据的内存。这种时候除开遵守老生常谈的“谁分配谁释放”原则外,剩下的基本也只能现场抓头发后悔定位了。
最先的入手点就是发生错误时所打出来的堆栈,按照经验跟着上面的错误信息后的第一条 Go routine backtrace 通常是发生问题的地方(应该……?)。可以先顺着调用栈检查一下代码中是否有不正确的指针使用。不过这个堆栈中只会存在 Go 这一部分的信息。当问题出现在 Go 之外的时候日志会变得非常迷惑,基本只能够知道是哪一个 CGO 函数值得怀疑。这一部分就和普通的内存问题排查差不多,列举几个常用的步骤:
ART 使用能动态调节大小(自适应 adaptive)的节点作为内部树节点,能够提高内存使用率。DBMS 中常见的有序索引数据结构B-tree或者传统的radix tree因为每个节点的大小是固定的,因此存在空间放大的问题。类似于磁盘或内存页表的大小,节点的大小通常需要取舍,节点太大的话浪费很严重,节点太小路径又很长,影响读写效率。